本文翻译自:Hecto, Chapter 5: A text editor – Philipp Flenker – Engineering Manager,封面图也来源自此。
现在 hecto 能读取文件了,让我们看看能不能让它也能编辑文件。
插入常规字符
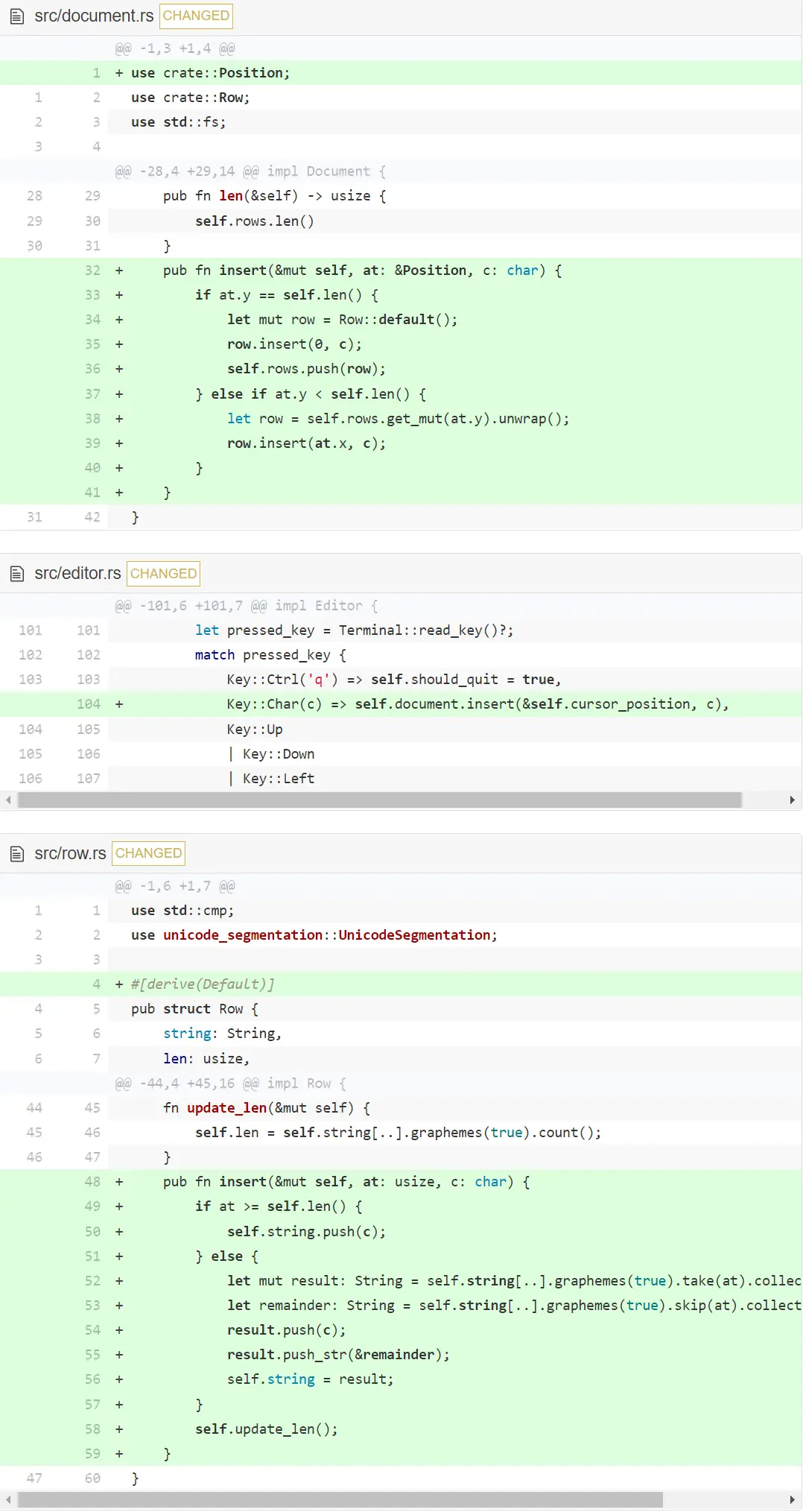
首先,让我们写一个函数,在给定的位置将字符插入到 Document 中。我们先在指定位置向字符串添加一个字符。
// 译者注:52-53 行代码如下
let mut result: String = self.string[..].graphemes(true).take(at).collect();
let mut remainder: String = self.string[..].grephemes(true).skip(at).collect();
先看看 Row 中的改动。我们处理了两种情况:如果插入位置碰巧在字符串末尾,则插入该字符。该情况发生于用户在行尾不断打字的情景下。另外一种情况,通过逐个遍历字符来重建字符串。我们使用了迭代器的 take 和 skip 函数来创建新的迭代器。一个迭代器从 0 到 at (包含 at ),另一个迭代器从at 后到末尾。我们使用 collect 来组合这两个迭代器为字符串。collect 非常有用并且能转换为不同的集合。因为 collect 能创建多种集合,所以我们需要声明 result 和 remainder 的类型,否则 Rust 无法知道创建的集合的类型。现在也为 Row 派生了 default。我们将在 Document 中使用它。
与 Row 中做法类似,我们要处理用户试图在 Document 底部插入字符的情况。对于该情况,创建一个新行即可。
我们需要在输入字符时调用这些方法。我们通过扩展 editor 中 process_keypress 的功能来实现。
有了这些改动,现在我们能在文档的任何位置添加字符。但是光标不会移动 — 所以我们实际上在倒着输入文本。让我们现在通过把 『输入一个字符』看成是『输入一个字符并向右移动』来修复这个问题。
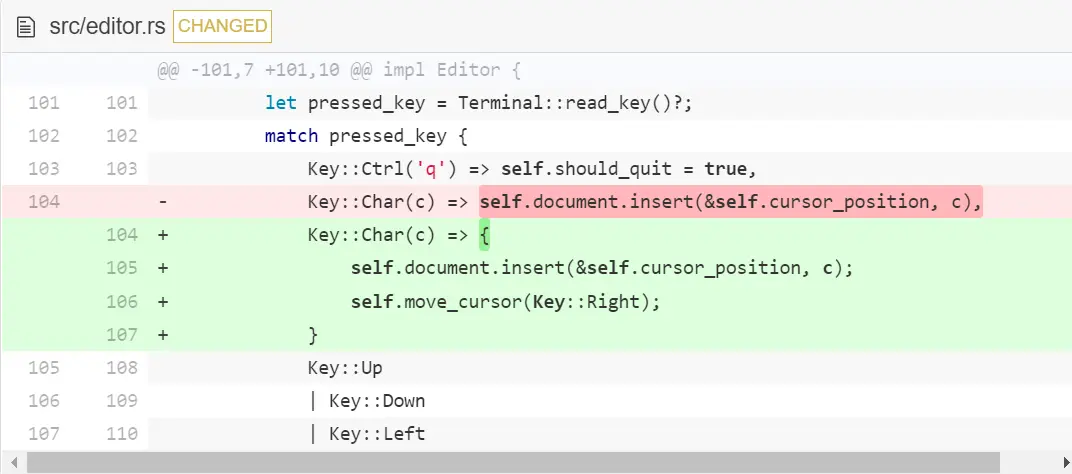
你现在能发现,插入字符是有效的,即便在文件底部也是有效的。
简单删除
我们现在想用一下退格键和删除键。
让我们从删除键开始。它应该删掉光标下的字符。如果你的光标是一根线 | 而不是方块,那么『光标下』表示『光标前』。因为这里的光标是一根在其左侧位置闪烁的线。
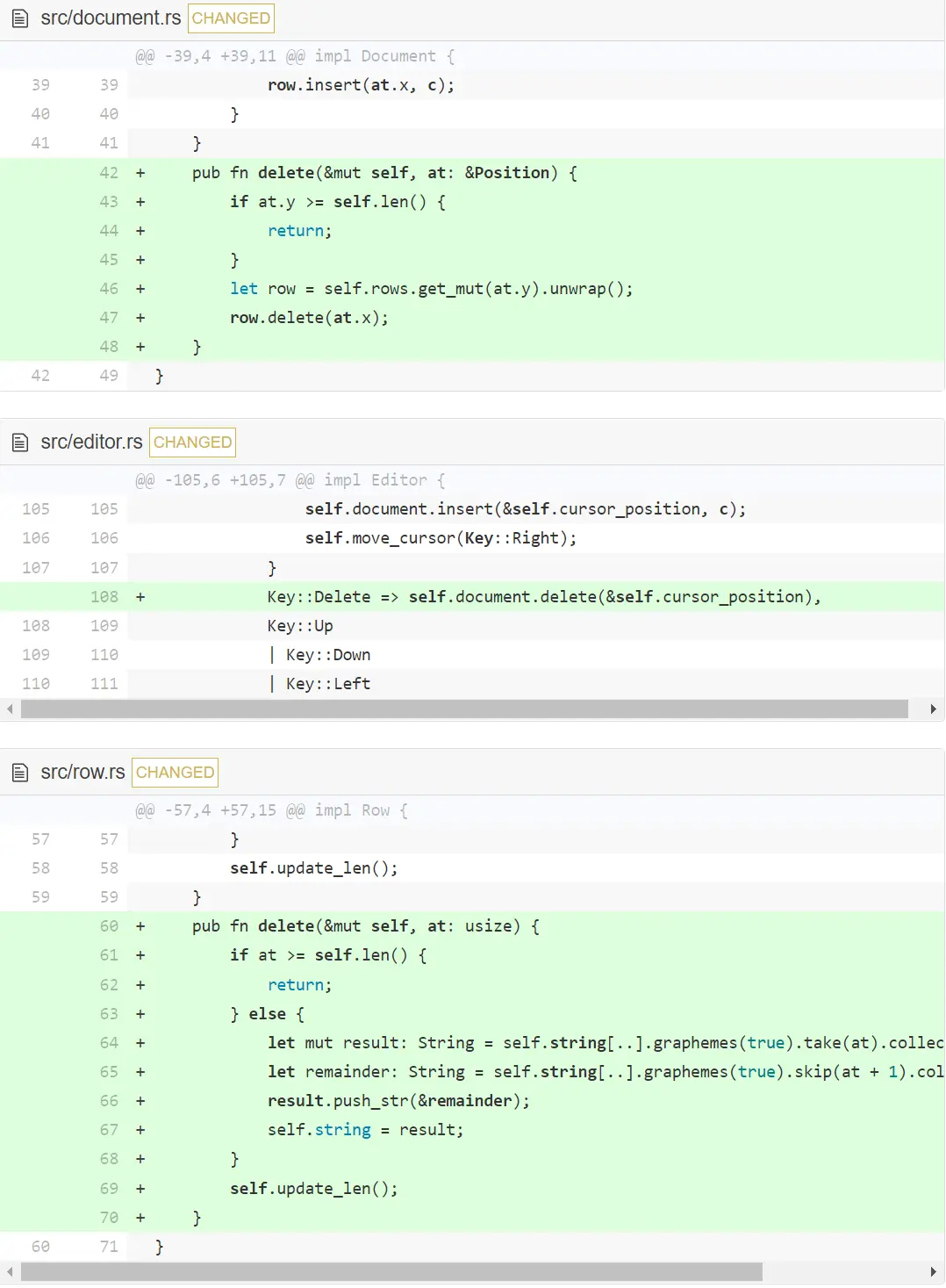
让我们先在 row 中添加一个 delete 函数吧。
// 译者注:64 和 65 行代码如下
let mut result: String = self.string[..].graphemes(true).take(at).collect();
let remainder: String = self.string[..].graphemes(true).skip(at + 1).collect();
如你所见,代码跟我们之前 insert 代码很像。区别是在 Row 中,我们不会添加字符,而是在拼接 result 和 remainder 时跳过要删除的字符。在 Document 中,我们还不需要处理删除一行的情况,而这让代码相比对称的 insert 代码来说简单一点。
你现在应该能删掉某行中的字符了。那下面让我们处理退格键:实际上,退格键是左移和删除的组合,所以像下面这样修改 process_keypress :
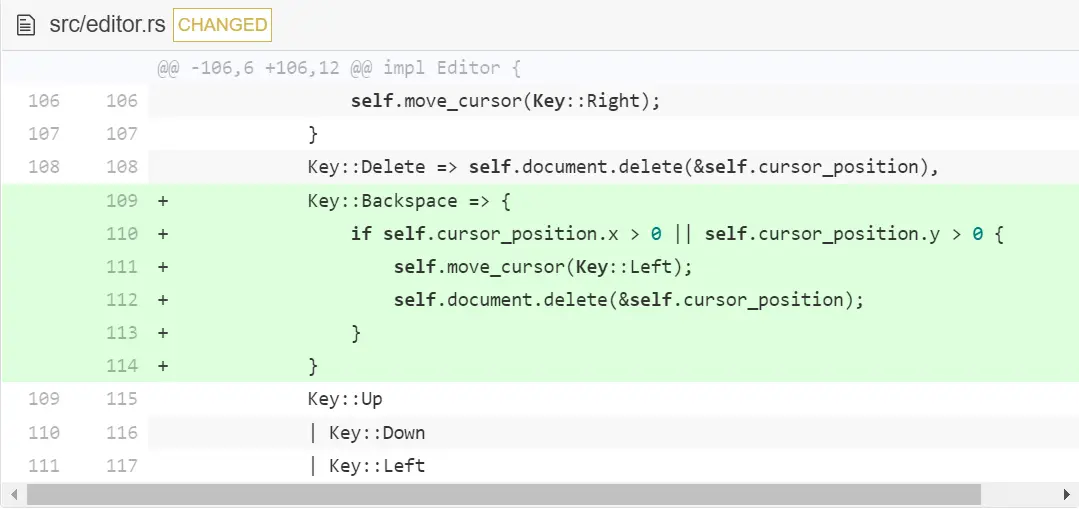
现在,退格键可以在每行中工作了。如果在文档开头,我们还确认不会做删除操作,否则会删掉光标下的字符。如果在行开头按下退格键,光标什么也没做,还移到了上一行。让我们在下一章修复这个问题。
复杂删除
有两个边界情况我们还没处理。其一是在行开头使用退格键,其二是在行尾使用删除键。在我们的情况下,退格键简单直接地向左移动,而这在行开头意味着需要移到前一行的结尾,然后尝试删除一个字符。这表明,只要我们允许在行末删除字符,退格键的问题就会得到解决。
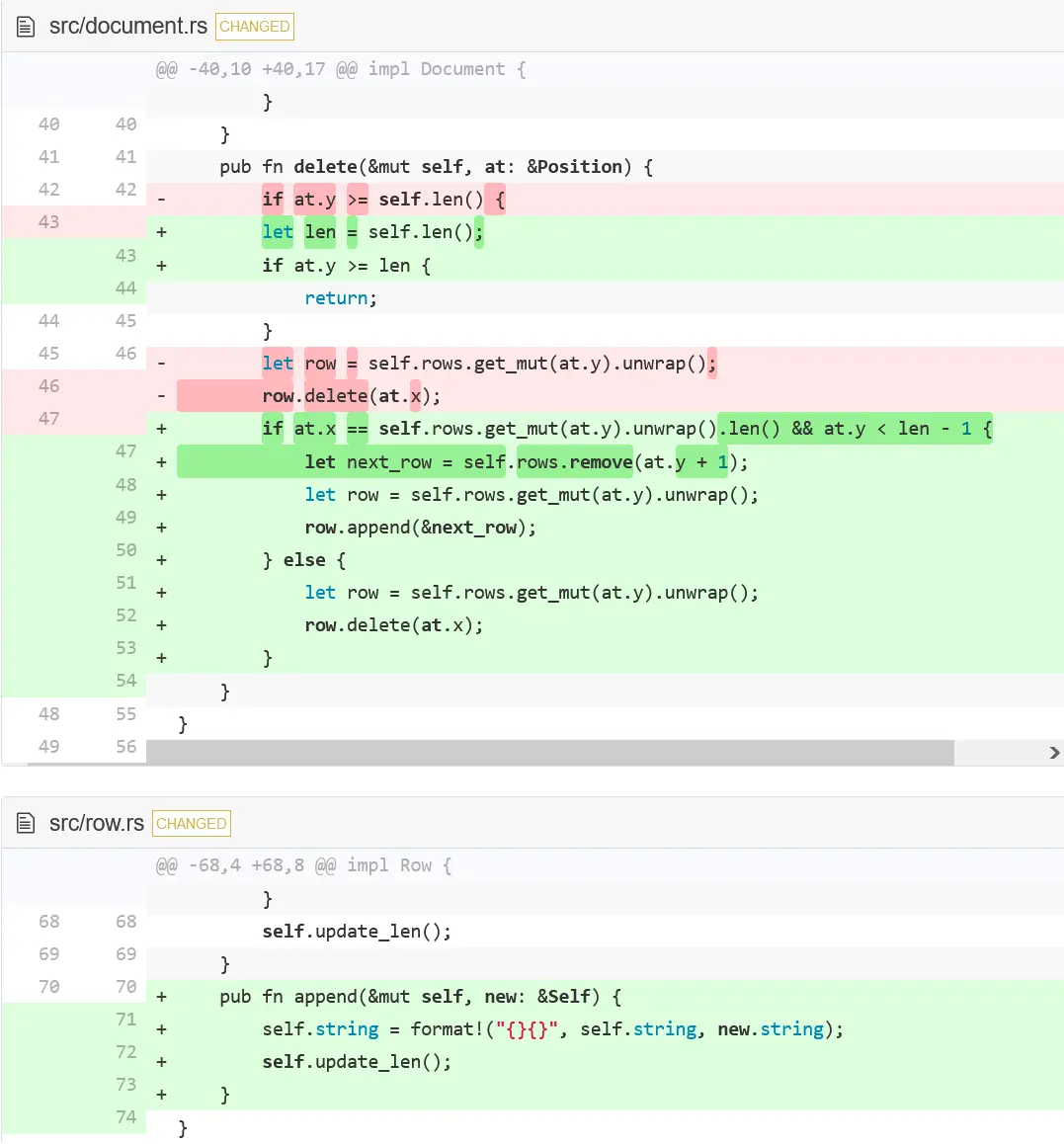
我们首先让 Row 能追加下一行字符串到它的末尾,并在 Document 中使用了这个功能。现在Document 中的代码看起来有点复杂,我马上解释为什么要这样。
它做的无非是检查是否在一行末尾,以及该行下面还有没有行了。如果条件都满足,我们就从 vector 中删除下面一行,并追加它到该行的末尾。如果条件不满足,只删除字符即可。那为什么现在代码看起来如此麻烦呢?我们不能把 row 的定义移到 if 语句的上面吗?这样还能清楚一些。
这是我们第二次遇到 Rust 的借用检查器。我们不能同时拥有两个指向 vector 内部元素的可变引用,也不能在有一个指向其内部元素的可变引用的时修改 vector。为什么呢?因为,假设有一个 vector,其中包含 A、B 和 C,我们有一个指向 B 的引用,引用类似于指向 B 内存地址的指针。现在删掉 A,这导致 B 和 C 向左移动。引用就不再指向 B 而是 C 了。这意味着我们不能在拥有一个 row 引用的前提下,删除该 vector 的部分元素。所以我们先直接读取了 row 的长度而没有存储一个引用。然后通过删除其中的元素来修改 vector,最后才创建了指向 row 的可变引用。
你可以修改一下代码,尝试你感兴趣的情况,看看编译器告诉了你些什么。
回车键
我们要实现的最后一个编辑器操作是回车(Enter)键。回车键让用户可以在文本中插入新行,或者将一行分割为两行。你现在实际上可以用这种方式添加新行,但是如你所料,其处理效果并不理想。这是因为新行是作为行的一部分插入的,而不是创建了一个新行。
让我们从一个简单例子开始,在当前行下添加一个新行。
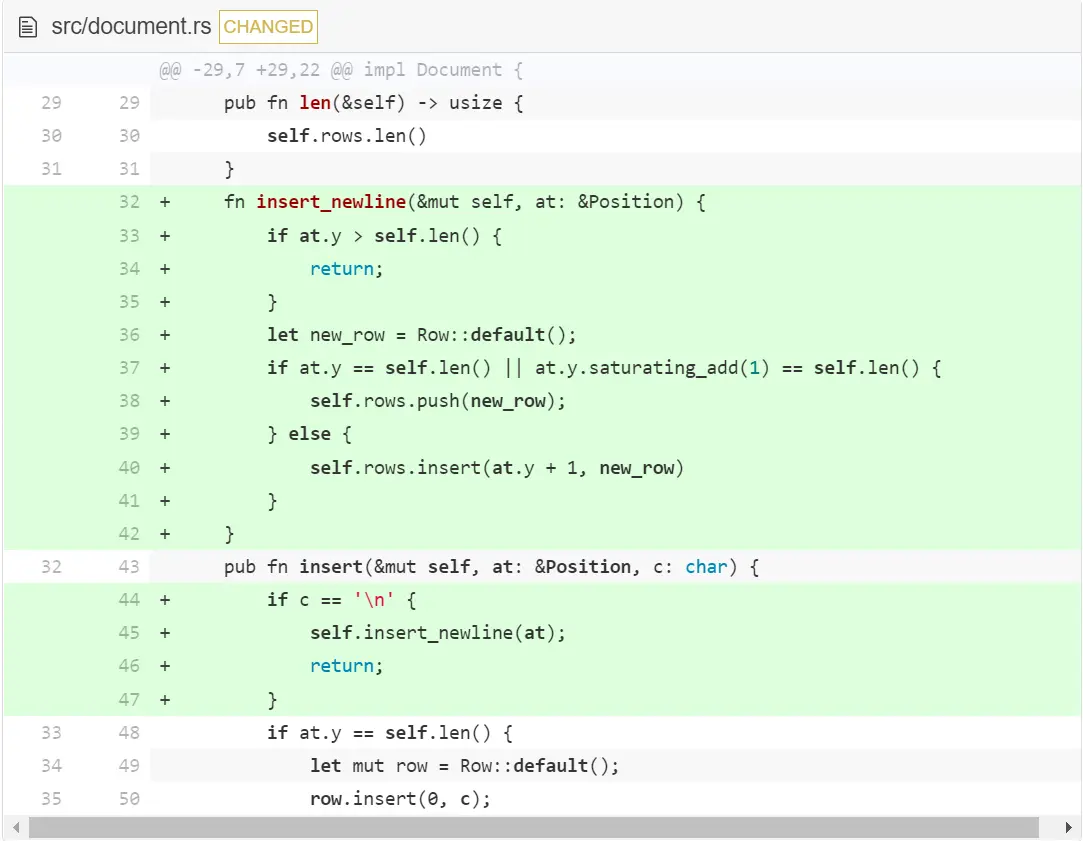
我们在 insert 中调用 insert_newline 来避免换行符插入的情况。在 insert_newline 中,检查回车键是不是在文档的最后一行或者它的下一行(记住光标允许移动到那)按下的。如果是这样的,我们就在 vector 后添加一个新行;如果不是这样的,就在相应位置插入一个新行。
现在让我们处理在行中间按回车的情况。
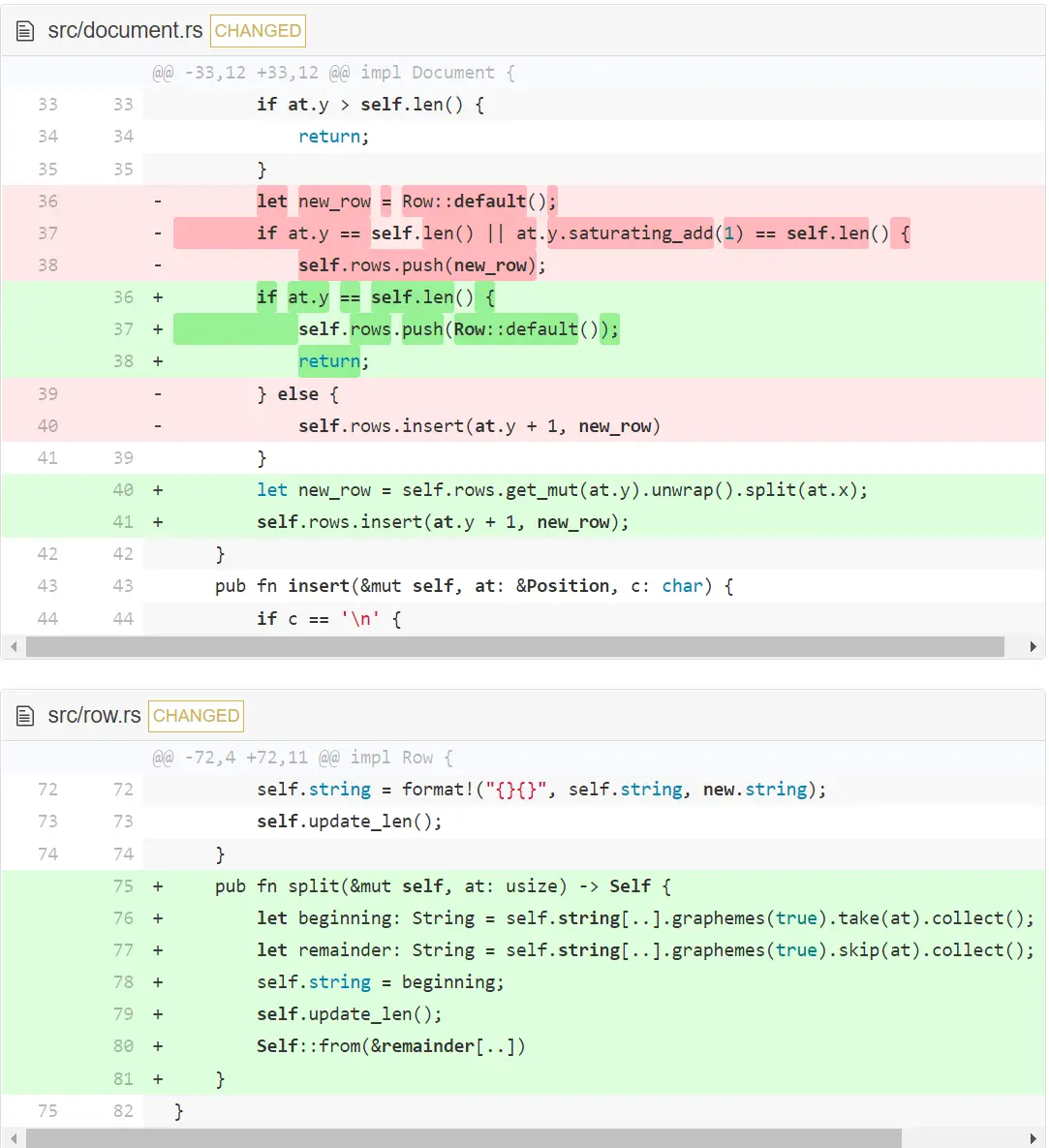
我们添加了一个叫 split 的方法。它截断当前行到给定索引处,并把索引后的所有字符作为下一行返回。在 Document 中,如果在最后一行下面我们就添加一个新的空行,否则,就用 split 修改当前行,并插入新的下一行。即使在行尾也是有效的,在该情况下新行将仅包含一个空字符串。
很好!现在我们能滚动浏览文档,添加空格和字符甚至是 emoij 还有删除行等等。但是没有保存的话,编辑显然是没用的。所以让我们下面实现一下保存功能。
保存到磁盘
终于实现了文本编辑器编辑功能,现在让我们实现保存到磁盘功能。从在 Document 中实现一个 save 方法开始。
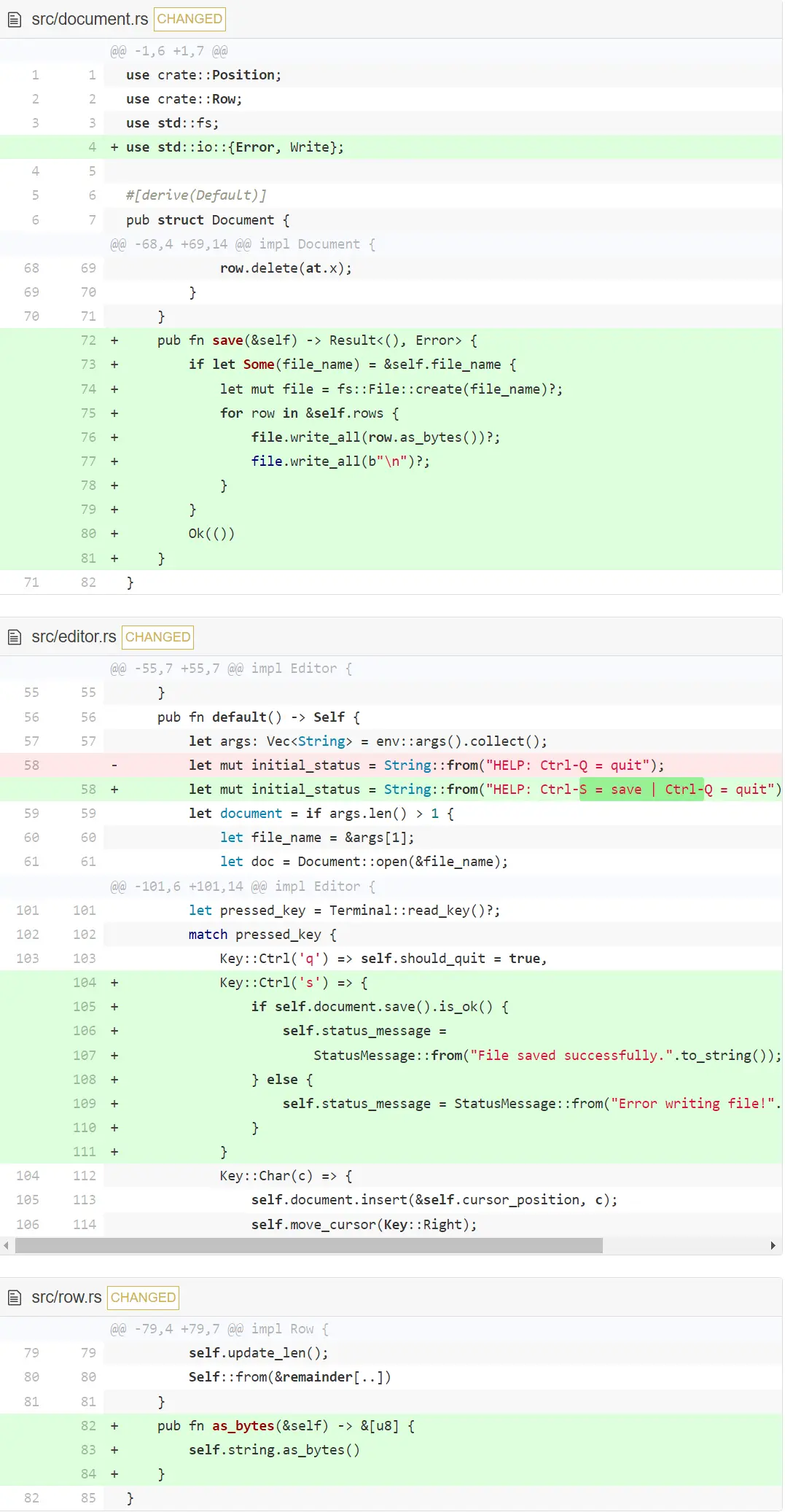
我们用一个可以将 row 转换为字节数组的方法扩展 Row 。在 Document 中,write_all 接收字节数组然后把它写入到磁盘中。因为 rows 不包含换行符,所以要单独写出来。换行符字符串前的 b 表示这是一个字节数组而不是字符串。因为写入磁盘可能会发生错误,所以 save 函数返回一个 Result。我们再次使用了 ? 来传递任何可能发生的错误给调用者。在 Editor 中,绑定 save 到 CTRL-S 上。通过 is_ok 检查是否保存成功,如果 Result 是 Ok 则返回 true,否则返回 Err,然后相应地设置状态信息。
最后也同样重要的是,修改了初始状态信息,来告诉用户怎样保存一个文件。很好,现在能打开、修改和保存文件了。
另存为……
现在,当用户无参运行 hecto 时,他们得到了一个空白文件但是没有办法保存。让我们写一个 prompt() 函数在状态栏展示提示。让用户在提示后输入一行文本。
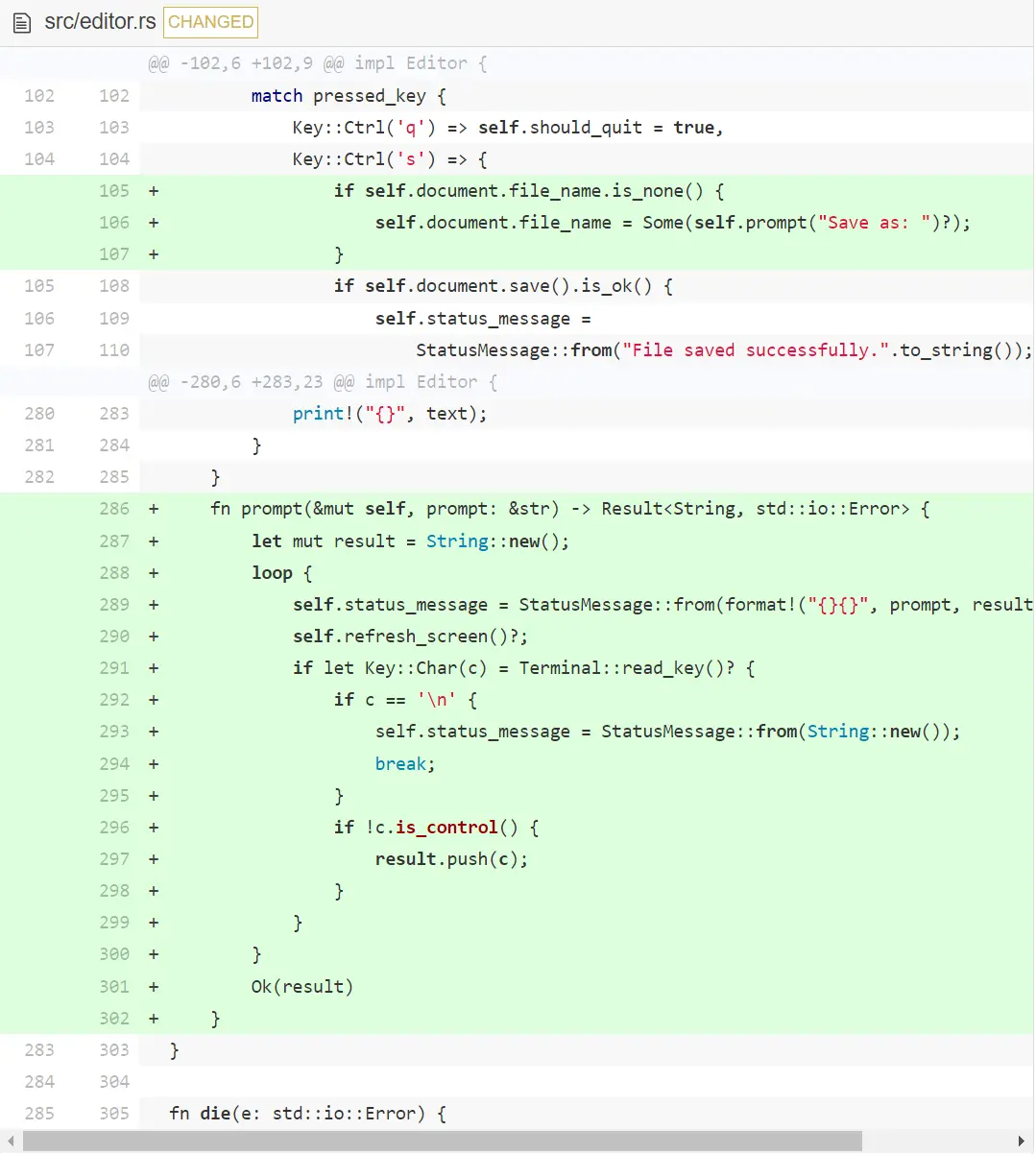
// 译者注:289 行代码如下
self.status_message = StatusMessage::from(format!("{}{}", prompt, result));
用户输入存储在 result ,它被初始化为空字符串。然后进入一个无限循环,重复设定状态信息,刷新屏幕和等待处理按下的按键。当用户按下回车,状态信息被清空然后返回该信息。期间可能发生的错误会被向上传播。
现在用户能够保存文件了,那就在 prompt中处理一些更多情况。现在让用户能取消输入和退格,也把空输入当作是取消。

// 译者注:save 函数如下
fn save(&mut self) {
if self.document.file_name.is_none() {
let new_name = self.prompt("Save as: ").unwrap_or(None);
if new_name.is_none() {
self.status_message = StatusMessage::from("Saved aborted.".to_string());
return;
}
self.document.file_name = new_name;
}
if self.document.save().is_ok() {
self.status_message = StatusMessage::from("File saved successfully.".to_string());
} else {
self.status_message = StatusMessage::from("Error writing file!".to_string());
}
}
这里我们改动了很多,一个一个地过一下。
prompt 不再只包含一个 Result,还包含了 Option。原理是如果成功提示,它仍然能返回 None,来表明用户终止了提示。还修改 if let 为 match ,来处理退格和 Esc 的情况。在 Esc 的情况下,重置先前输入的文本然后停止循环。在退格的情况下,删除最后一个字符,把输入的长度减一。然后,在 process_keypress 外建了一个新函数 save。其中,如果 prompt 返回 None 或者返回一个错误,就终止保存操作。
脏标志
我们要记录加载进编辑器的文本跟文件中的文本是不是不一样的。这样就能在尝试退出时,警告用户可能会丢弃没有保存的改动。
如果 Document 在打开或保存后被修改过,我们称其为『脏』。在 Document 中添加一个 dirty 变量,初始化它为 false。我们不想在外面修改它,所以添加一个只读的 is_dirty 函数。文本改动后设定 dirty 为 true ,save 后设定为 true。
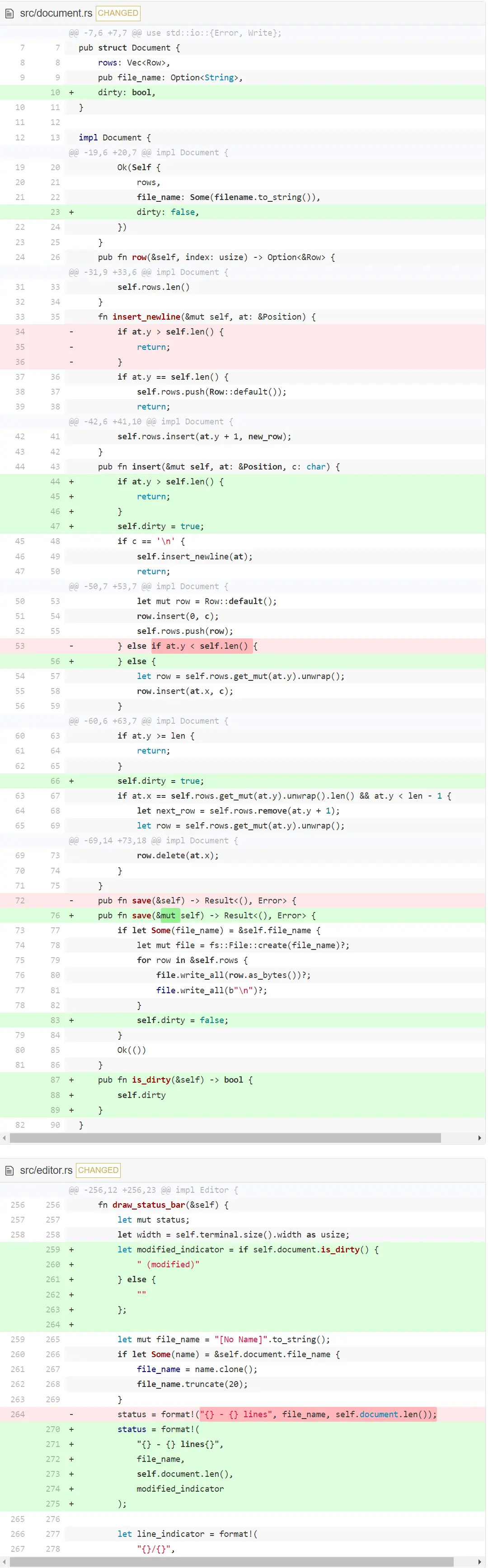
可能唯一让人意外的改动是重新安排了insert 的边界检查。这样就和 delete 中的检查类似了。
退出确认
现在我们准备在尝试退出时,警告用户没有保存改动。如果 document.is_dirty() 是 true,我们会在状态栏展示警告,并要求用户按 3 次 CTRL-Q 来不保存退出。
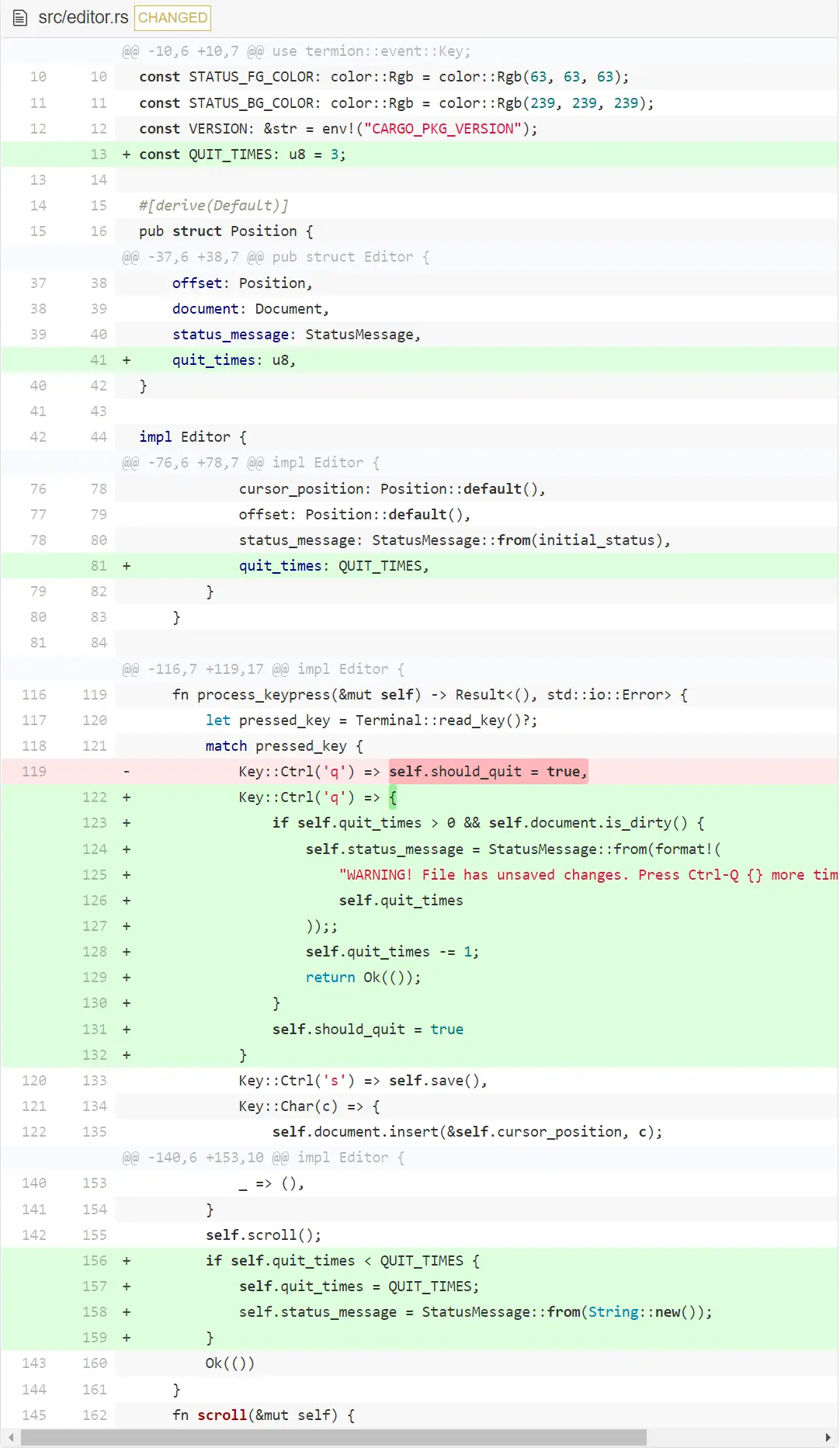
我们添加了一个新常量来设定用户需要额外按 CTRL-Q 的次数。用它作为 Editor 中的一个字段。当文档是脏的并且用户想要退出时,递减 quit_times 直到为 0 才退出。注意我们在 match 匹配臂返回值来退出。这样,match 后面的代码只有在用户按下除 CTRL-Q 外的其它键时才会被调用。所以,我们能在 match 后检查 quit_times 是否被修改,如果需要的话,重置为默认值。
最后润色
恭喜,你开发了一个文本编辑器!但是,在继续添加更多功能之前,让我们检查是否真的足够应付基本操作。在教程的前面,我们关心溢出和 saturated_add 等问题,但我们真的准备好处理更大的文件了吗,还是说 hecto 会 panic?另外,由于 Rust 是为性能而生的,我们的代码性能足够好吗?
首先,教 Clippy 一些新技能。
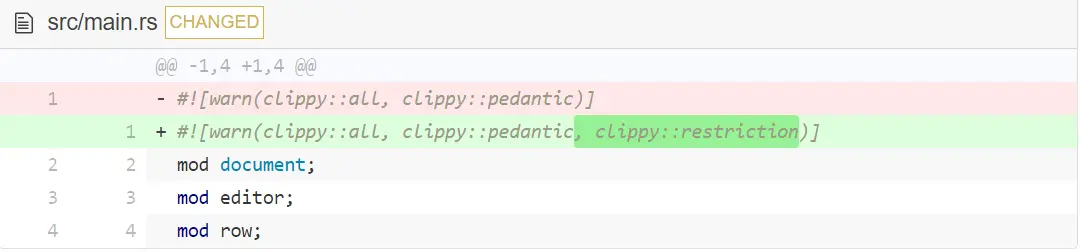
clippy::restriction 包含一些代码中可能会也可能不会表示错误的警告。如你所见,当你现在运行 cargo clippy,结果是吓人的。不过还好,每一项警告都有链接和一些解释。
让我们为 hecto 关掉一些警告项:
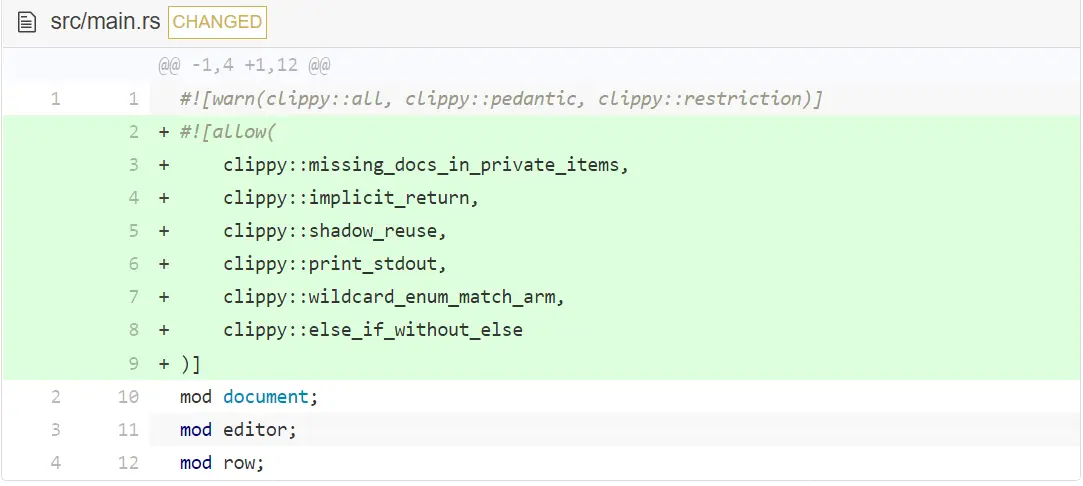
如果你对这些选项感兴趣,可以查看原来 Clippy 输出中的详细介绍。
现在 Clippy 的结果更容易管理了。不过,仍然有很多关于整数加法的警告。在讨论它们之前,先扪心自问:我们真的要修复所有的警告吗?我的观点为:是的。两个原因:
- 一是一些代码依赖于函数背后的隐性约定:我们靠代码的其它部分检查,所以不必再次检查。但是如果将来其它部分发生改变呢?
- 另一个考虑是,如果遇到像
a+1的代码,你需要停下检查周围的代码,来看看该操作是否有效。你没有线索表明代码的作者(可能是过去的自己)是否注意到了潜在的溢出风险。最容易的方法是在该行关掉 Clippy 检查。即便是这种懒方案,对于后来审查代码的人来说,也是一个标记,表明你确实考虑到了溢出问题,并有意识地决定如何处理它。
话不多话,开始修改!
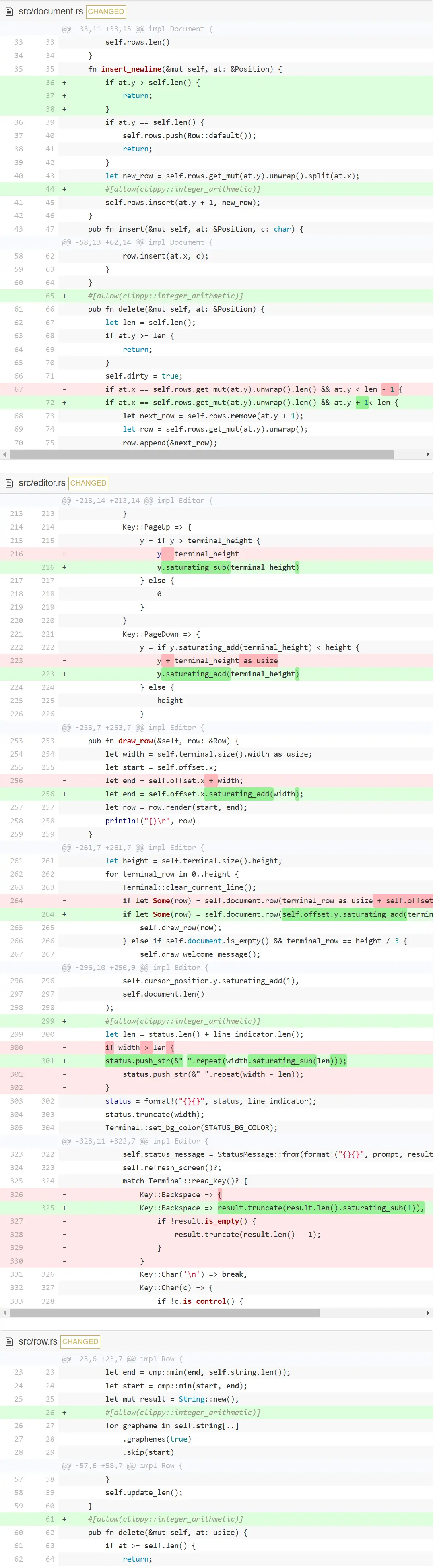
让 Clippy 满意
// 译者注:document.rs 中 264 行代码如下:
if let Some(row) = self.document.row(self.offset.y.saturating_add(terminal_row as usize)) {
如你所见,这些主要是小改动。我想重点说几件事:
- 我们发现了潜在的 bug 或是说让人头疼的事。比如,上次改动后,
insert_newline不再自己做边界检查了。单独看insert_newline不太可能理解没做边界检查的原因。因为,现在insert_newline只被insert调用,在insert中已经做了边界检查。这意味着对insert_newline的调用者来说,有一种隐式的约定,必须确保at.y没超过现在文档的长度。所以现在纠正了过来。 - 我们在在另一个地方用
at.y的加法代替了len的减法。为什么呢?因为很轻松就能发现该函数中的y总是小于len,所以总是有空间来加 1 。但len总大于 0,就不那么容易看到了。(译者注,len类型是usize,如果是 0 再减 1 会变成 usize 的最大值,即溢出。关于溢出的内容可以查看第三章。) - 当使用
saturating_sub时,能避免一些大小比较,从而简化代码。
Clippy 仍然给出了一些警告。这次是关于整数除法的。问题如下:如果你做除法,比如 100/3 ,结果会是 33 ,余数会被删掉。在我们的例子中,这是没问题的,但是没问题的原因跟前面说的一样 — 任何审核我们代码的人不能保证我们是否考虑到了这些,甚至是忘记考虑。我们至少可以做的是留下注释或是 Clippy 声明,它其实和注释一样,都在说『相信我,这玩意能运行』。
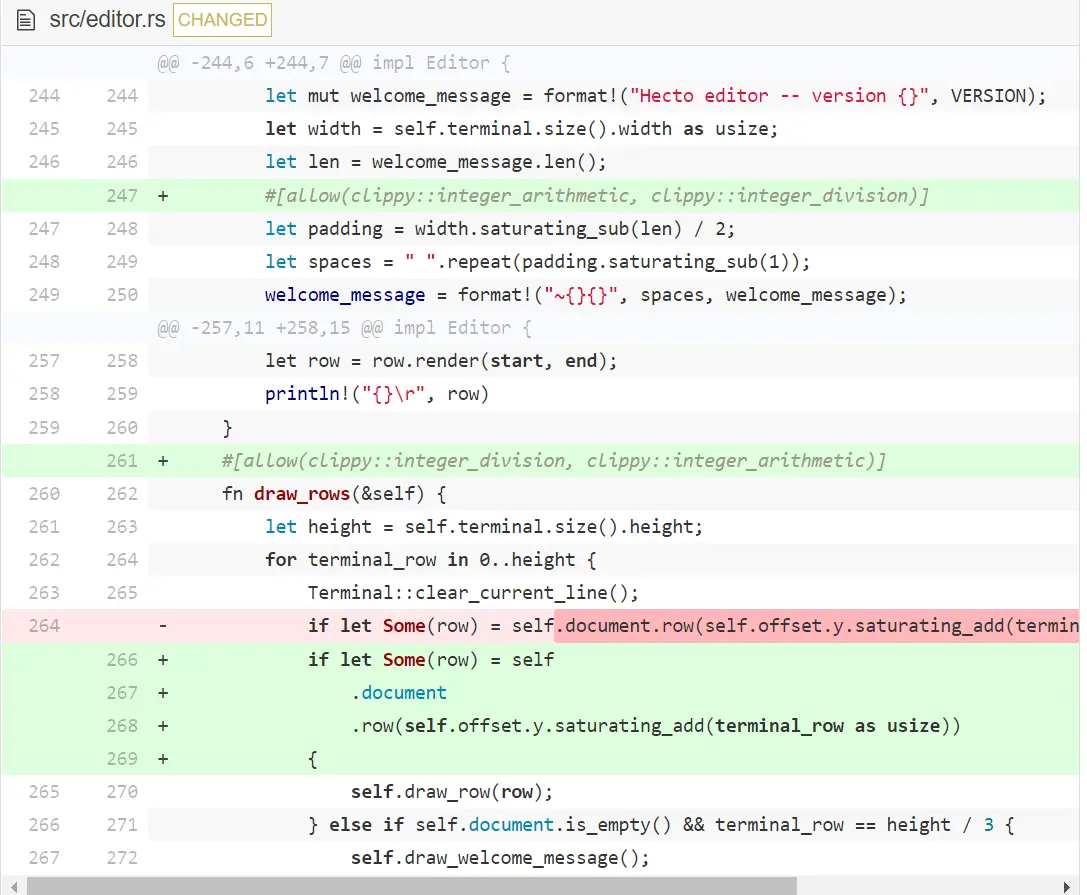
如你所见,我们在这采用了『留下注释』的解决方法。我们也重新缩进的一些代码,因为行现在太长了。
现在来解决 Clippy 的下一个警告。
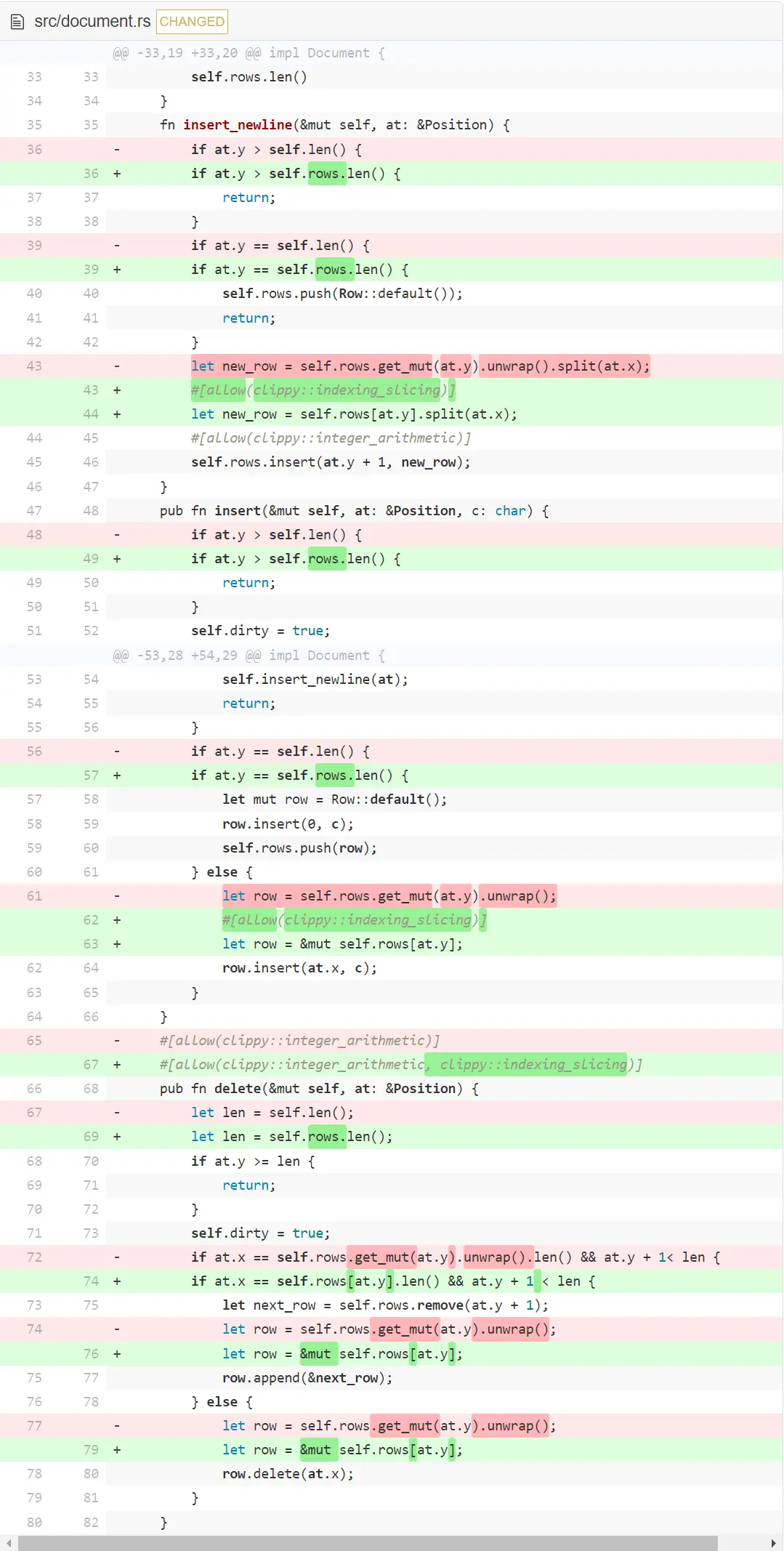
这次改动主要关于访问行的某个位置。以前用安全方法 get_mut,即使没有东西可以访问,比如索引是错的,它也不会 panic 。我们直接在它上面调用 unwrap() ,忽视了开始就用 get_mut 的好处。现在我们用直接访问 self.rows 来代替它。我们在所有地方都留下了 Clippy 声明语句,以表明确实检查了 — 当时只访问了有效索引。如果你想让代码更加鲁棒,可以用恰当的处理方法来替代它们,以免索引越界。
我们还改了另外的东西:还存在一个隐性约定,那就是文档的长度总是等于里面的行数,所以我们在任何地方都调用 self.len() 而不是 self.rows.len()。 假如我们决定文档可以更长,那对 self.row 的所有操作都会失败。这不是一个很重要的改动,但它符合目前重构的精神(译者注:该改动在 Cargo 1.59 版本的 Clippy 中没有报警告)。
好吧,还有两个 Clippy 警告。
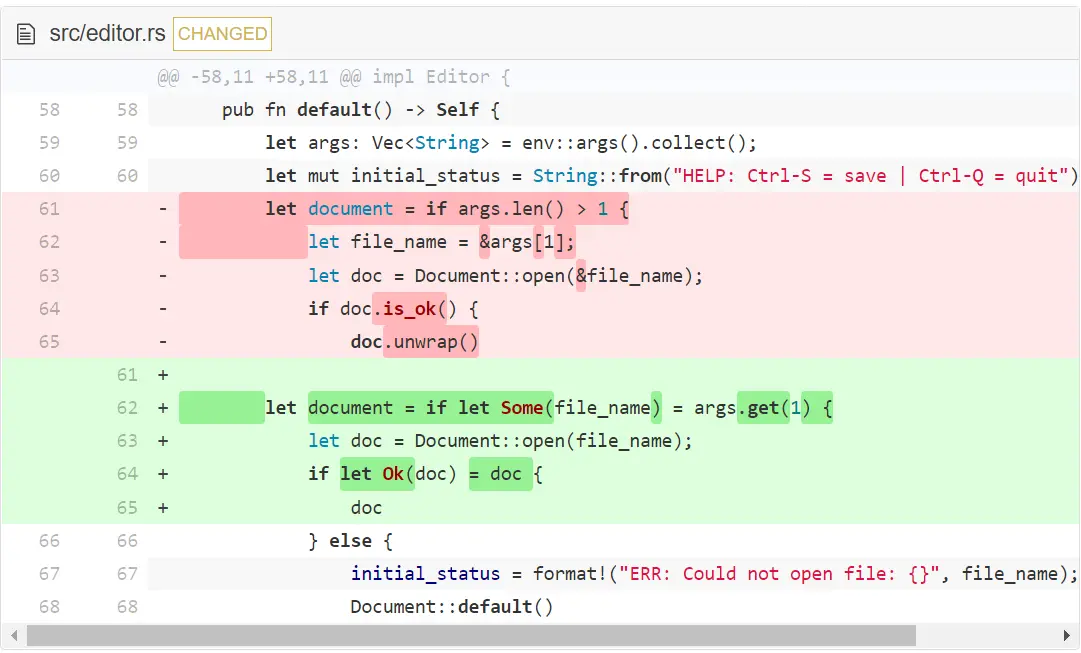
我们利用了这样一个特点,像上面讨论的那样,get 只在值存在的情况下返回,这样就不需要在访问索引元素之前检查。然后,有了 if_let 的帮助,我们删掉了 is_ok() ,从而省去用 save()。最后,我们说服了 Clippy 和自己,代码是好的!(译者注:现在版本的 Clippy 还有一些警告,同样,我们还是不去修改,读者只需理解 Clippy 的用处 — 通过 Clippy 来让代码变得更加鲁棒)
现在,有一些问题 Clippy 不能检测,在开发过程中,我们不应该只依赖 Clippy 。我们会在下面处理这些问题。
性能提升
目前为止,我们的编辑器并没做太多工作。但是已经有一些可以做的性能提升了!性能调整是一个困难的话题,因为很难在可读性、可维护性和难以阅读和维护之间划清界限。我们不想 hecto 成为最快的编辑器,但在一些性能方面考虑一下还是有意义的。
我希望我们在从上到下浏览文档时,注意不必要的行迭代,以及从左到右浏览一行时,注意不必要的字符迭代。这就是我们现在要关注的所有内容 — 不要额外的缓存,不要花里胡哨的技巧,只寻找多余的操作。
让我们把注意力放到怎样处理行上来。我们重复了一个相似模式很多次。比如,这里的 insert:
pub fn insert(&mut self, at: usize, c: char) {
if at >= self.len() {
self.string.push(c);
} else {
let mut result: String = self.string[..].graphemes(true).take(at).collect();
let remainder: String = self.string[..].graphemes(true).skip(at).collect();
result.push(c);
result.push_str(&remainder);
self.string = result;
}
self.update_len();
}
在该实现中,我们遍历字符串 3 次:
- 第一次是从头到
at来计算result; - 第二次是从头到尾(忽略头到
at的所有字符)来计算remainder; - 最后一次是遍历整个字符串来更新
len。
这不够好,让我们重构一下它。

我们在这做了两件事:
- 避免用
update_len,现在我们在每次行操作时手动计算长度。 - 对
enumerate遍历,它不仅提供下一个元素,还有该元素在当前迭代器中的索引。这样,我们就可以在行中移动时轻松计算长度。
最后的思考
毫无疑问,经过这些改动后,我们让 hecto 变得更好,让我们考虑地更深一些:我们有多大可能看到 usize 发生溢出?其实,这取决于你的操作系统。可以通过下面的代码片段查看 usize 的实际大小:
fn main() {
dbg!(std::usize::MAX);
}
在我的机器上,它输出下面的结果:
[src/main.rs:2] std::usize::MAX = 18446744073709551615
这表示,只要文档接近 18,446,744,073,709,551,615 行或者行接近18,446,744,073,709,551,615 个字符,就会发生溢出。这是很大的数。如果每行包含一字节信息,那会有 18 EB 的数据。EB 表示艾字节(Exabyte,$10^9 GB$)。希望你能找到可以处理这么大数据的硬盘!即使你能找到,在处理这种体量的数据时,hecto 会遇到其它问题。
这不表示我们的思考是不重要的。相反,我认为当你在编写代码时,应该把考虑这种事作为一种习惯。当然,你也不要为一个从不会发生的特例过度优化代码。
结论
现在,你成功开发了一个文本编辑器。如果足够有勇气,你可以用 hecto 来开发 hecto 。在下一章中,我们会利用 prompt() 来在编辑器中实现一个增量搜索功能。