本文翻译自:Hecto, Chapter 2: Reading User Input – Philipp Flenker – Engineering Manager,封面图也来源自此。
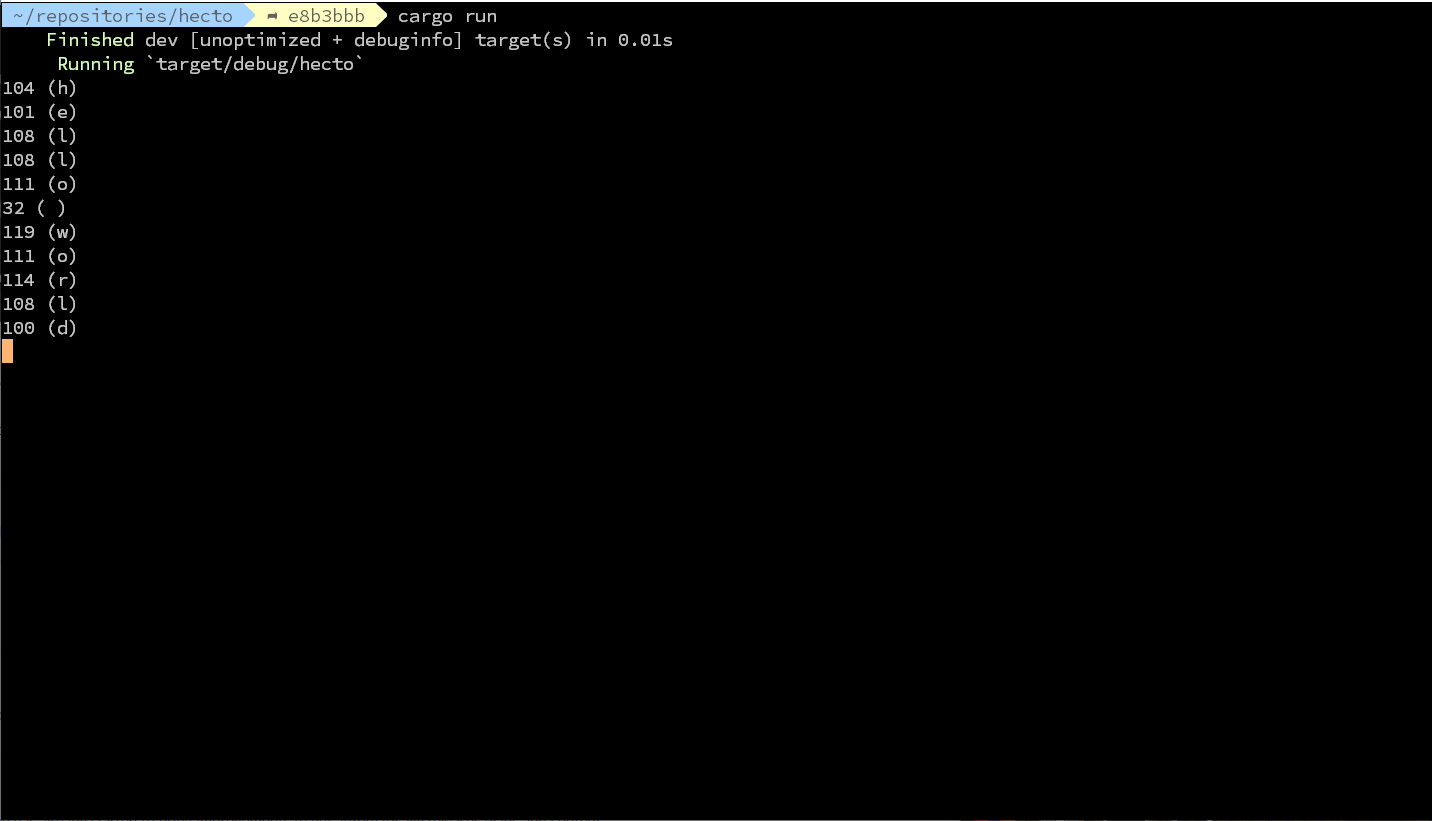
我们尝试读取一下用户的按键信息。在 main 函数中删除“Hello, world”,然后像下面这样修改代码:
运行一下这个程序,尝试搞清楚它是怎样运行的。按下 CTRL-C 来停止这个程序。
首先,我们要使用 use 导入一些东西到我们的程序中。我们要利用系统的输入/输出(简称为 io)做一些事情。因此,我们使用 use std::io::{self, Read} 来导入 io 库,该命令是下面的简写:
use std::io;
use std::io::Read;
之后,我们就可以在我们的代码中使用 io 库。并且通过引入 Read 到代码中,我们就能使用bytes()。尝试跑一下你没导入 Read 的代码,编译器会退出并打印 『Read 需要被引入到作用域(Scope)中』错误,因为 Read 会导入 bytes() 的实现。
# 译者注:最终报错信息如下
**help: the following trait is implemented but not in scope; perhaps add a `use` for it:
|
1 | use std::io::Read;
|**
这个概念被称作 Trait ,我们会在后面的教程中深入了解。关于 traits 的文档是你必须要读的!
如果你刚接触 Rust,不要慌。虽然在这一章中,我们有很多要学的,但是将来添加的代码不会像这次一样一次引入很多新概念。当然,随着教程的深入,一些概念会变得越来越清楚,所以,如果你没有立刻明白所有的概念,不要担心。
main 函数的第一行同时做了很多事情,可以总结为『 把你从键盘输入中读取到的所有字节绑定到 b 然后执行下面的代码块(block)』。
让我们现在解释下面几行。io:stdin() 表示你想要从 io 中调用一个叫做 stdin 的方法(io 是我们唯一导入的库)stdin 代表标准输入输出。简言之,它给你所有可以输入到程序中(数据流)的访问权限。
对 io:stdin() 调用的 bytes() 返回我们可以遍历的东西。换句话说,一些可以让我们在元素序列上执行相同任务的东西。跟大多数语言相似,在 Rust 中,这个概念被叫作迭代器。
使用迭代器可以让我们用 for..in 构造一个循环。结合 for..in 和 bytes() ,我们是在让 Rust 从标准输入中读取字节到变量 b中,然后持续下去,直到没有更多的字节可供读取为止。for..in 之后的两行代码打印输出每一个字符(我们一会再解释 unwrap 和 println! ),如果没有字符可以读取就返回。
当你运行 ./hetco (译者注:需要切换到 target/debug/ 目录下,或者直接输入 cargo run )后,终端和标准输入连接起来,所以你的键盘输入会被读取到变量 b 中。然而,默认情况下,终端以 canonical mode (规范模式),也叫 cooked mode(成熟模式)运行。在这种模式下,键盘输入只会在用户按下回车键后被输入到程序中。这对大部分程序来说是有用的:让用户输入一行文字,使用退格修正错误直到输入跟用户想要的相同为止。最后按下回车,发送输入的文字到程序中。但是,这种方式对于需要更复杂用户界面的程序来说不太方便,比如文本编辑器。我们想要在输入时处理每个按键输入,这样我们就可以立刻与之交互。
为了退出上面的程序,按下 CTRL-D 来告诉 Rust 到达了文件尾。或者你也可以随时按下 CTRL-C 来示意进程马上结束。
我们想要的模式是原始模式(raw mode)。幸好,有一些可供我们设置终端为原始模式的外部库(external libraries)。库在 Rust 中被称作 crate — 如果你想阅读关于它的内容,这里是文档链接。跟其他程序设计语言差不多,Rust 采用一个精简核心 — 依赖 crate 扩展功能。在这篇教程中,我们有时会首先手动实现一些东西,然后切换到外部库函数;而有时会直接调用外部库函数。
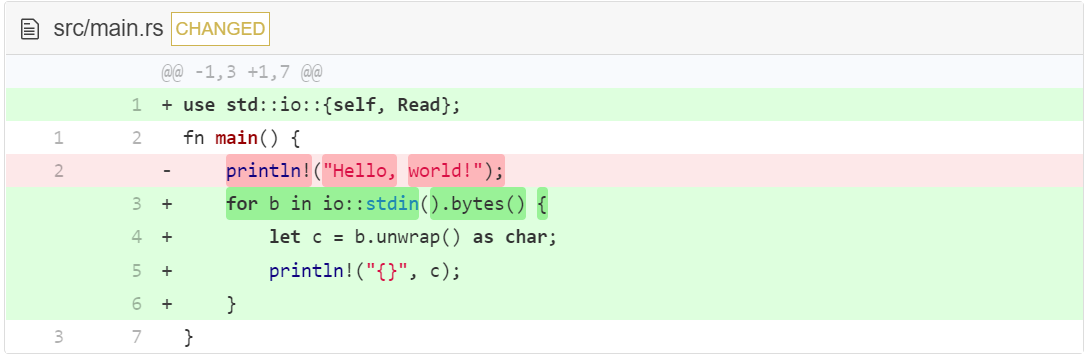
按下 Q 退出?
为了展示 canonical mode (规范模式)怎样工作,我们会让程序在读到用户输入的 Q 键后退出。
需要注意的是,在 Rust 中字符需要单引号包裹,而不是双引号。
为了退出程序,你不得不输入一行包含一个 q 的文字,然后按下回车。程序会迅速从该行文字一个字符一个字符的读入,直到读到 q,这时 for..in 循环会停止,程序会退出。所有在 q 之后的字符不会被读取,也不会被打印输出。Rust 在退出时忽略了它们。
使用 Termion 进入原始模式(raw mode)
像下面这样修改 cargo.toml:
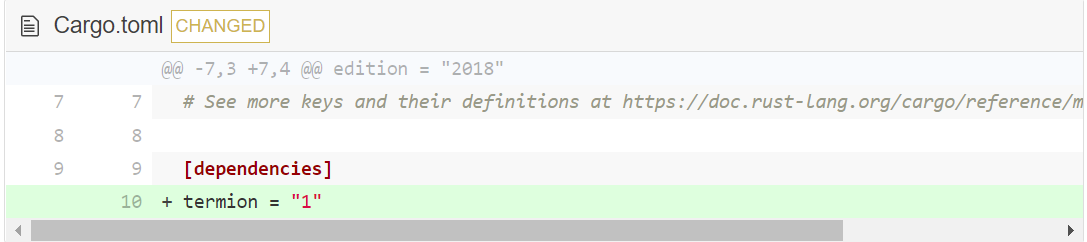
通过这种方式,我们在告诉 Cargo 我们想有一个叫作 termion 的依赖,版本号是 1 。Cargo 遵循语义化版本的概念,程序的版本通常由三个数字构成(比如 0.1.0)。按照惯例,只要第一个数字保持不变,就表示没有巨大的改动。这意味着,如果你基于 termion v1.5.0 开发,程序同样会在 termion v1.5.1 甚至是 termion v1.7.0 版本正常运行。这是有用的,因为意味着我们在修复 Bug 和开发新功能的同时,现存的功能可以保证正常运行而不需要修改代码。通过设置 termion = "1", 确保能获得始于 1 的最新版本。
等到你运行 cargo build 或者 cargo run 的时候,新的依赖 termion 会被下载并编译,输出如下所示:
**Compiling libc v0.2.62
Compiling numtoa v0.1.0
Compiling termion v1.5.3
Compiling hecto v0.1.0 (/home/philipp/repositories/hecto)
Finished dev [unoptimized + debuginfo] target(s) in 7.83s**
如你所见,termion 和它的依赖一同被 cargo 下载并编译。你可能会注意到 Cargo.lock 也发生了变化:现在包含了所有安装的库和依赖的确切名字和版本。如果你在一个团队中工作,这对避免”在我机器上可以运行(Works on my machine)“ Bug 很有帮助 — 你遇到了 Bug,比如在 termion v1.2.3 中,而你的同事在termion v1.2.4 上工作,却没有发现这个 Bug。
如果你没有读最开始的章节,这个教程不能在 Windows 上完成。Termion 是一个不支持 Windows 平台的依赖,但是你可以使用 Linux 子系统(译者注:WSL)运行程序。
在写这篇教程的时候,Termion 是唯一选择。现在,教程发布后的两年,有一个可用的跨平台的库 crossterm 。它与 Termion 的调用方式不同,所以,如果你选择使用 Windows 而不是 Linux 系统的话,不能直接跟着教程做。但是,如果你有软件开发的背景,你可能会发现迁移 Termion 到 crossterm 很容易且很吸引人。
如果你想要找一些关于怎样使用 crossterm 运行程序的建议,看一下这个不错的改进版 hecto,它可以运行在所有的平台。(译者注:官方称支持的平台包括 Linux 和 Windows平台)
现在像下面这样修改 main.rs:
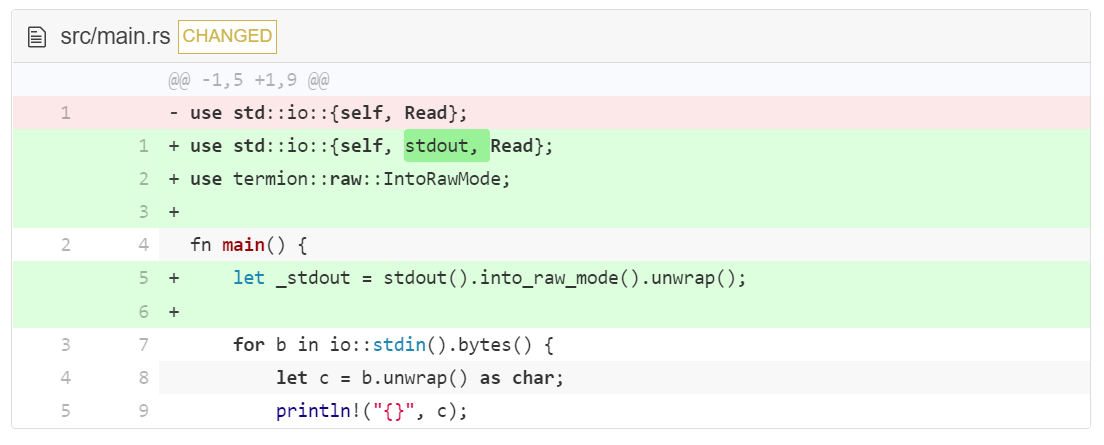
尝试运行一下,你会注意到每一个输入的字符被立刻打印输出,并且只要你输入 q,程序便退出。
所以,我们做了什么? 这有一些事需要重点说说。
第一,我们通过函数 into_raw_mode() 来用 termion 提供的标准输出,即上面我们调用的 stdout(与上面 io::stdin 相似的东西)。但是为什么我们调用 stdout 中的方法来修改 stdin 的读取方式呢?答案是终端的状态被写者(Writer)控制,而不是读者(Reader)。写者被用来在屏幕上绘制图像或是移动光标,所以(stdout)经常被用来改变模式。
第二,我们把 into_raw_mode() 的结果赋值给 _stdout 变量,但是我们没有对这个变量做任何操作。这是为什么呢?因为这是我们第一次遇到 Rust 的所有权系统 。总结一下这个复杂的概念:函数可以拥有某些东西,未拥有的东西则会被删除。into_raw_mode() 修改了终端,并返回了一个值,它一旦被移除会重置终端为 canonical mode (规范模式),因此我们需要让它持续绑定在 _stdout 上。你可以尝试去掉 let _stdout= ,终端不会保持原始模式(raw mode)开启。
通过在变量(名称)前加下划线 _ ,我们是在告诉其他阅读我们代码的人我们只是在保持 _stdout (有效),即使不会用它。相应地,如果你有一个未曾使用的变量不是以下划线开头,编译器会认为你犯了错并警告你。
尽管所有权系统是复杂的,现在你不需要完全理解。你会随着教程的进行越来越明白。
观察按键按下
为了详细了解原始模式(raw mode)下的输入是怎样工作的,让我们改进一下每个读取到的字符的输出方式。
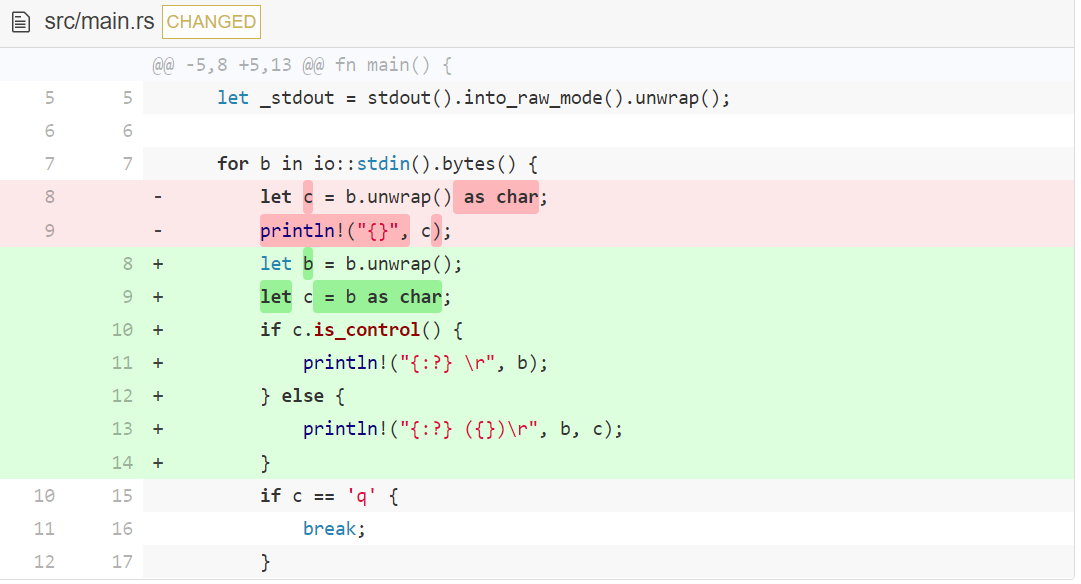
在我们讨论新功能之前,让我们先迅速过一下改动。
首先,我们不再只打印字符 c, 和字节码 b 。为了防止你对 b 有些疑惑:在 Rust 中,声明一个变量两次是完全符合语法规则的。我们首先在 for b in... 中声明了 b ,然后用 let b = b.unwrap() 再次声明。这被称为变量隐藏(variable shadowing)。它是非常有帮助的。第一个 b 对于我们来讲不再有用,因为我们只想使用『未包裹(unwrapped)』的值(我承诺,我们会马上解释它的意思)。变量隐藏(variable shadowing)可以确保我们不必处理两个变量,比如 b_wrapped 和 b 。试着把 let b...中的 let 去掉,玩一玩这个概念。
顺便提一下,as 关键字尝试将基本类型转化为其他基本类型。在我们的例子中,一个字节(byte)类型被转换为 Char 类型。
is_control() 判断某个字符是否是一个 控制(Control) 符。控制(Control)符是不可打印 — 不希望输出到屏幕的字符。ASCII 编码中的 0-31 和 127 是控制符。ASCII 码中 32-126 都是可打印的。(查看 ASCII 码表中所有的字符)。
println! 是一种宏,它将其输入打印成单行。传递给 println! 参数中的 {} 和 {:?} 是占位符,它们会被剩下的参数填充。因此,println!("This is a char: {}", 'c'); 会打印输出 “This is char: c”。占位符 {} 用来替代那些已知字符串表示的元素(译者注:即实现了 std::fmt::Display trait 的类型),比如 char。{:?} 用来替代那些字符串表示未知,但是实现了 debug 字符串表示的元素(译者注:即实现了 std::fmt::Debug trait 的类型)。为理解其中的差异,尝试切换 {} 和 {:?} 然后看一下发生了什么(尽管理解其中的差异对于开发 hecto 并不重要)。
译者注:关于格式化输出的内容,可以查看这个链接。
我们也在每行的结尾打印输出了 \r (回车 Carriage Return)。这确保我们的输出被一行一行的整洁打印没有缩进。回车(Carriage Return) 在 println! 添加新行\n之前,移动光标到回到当前行的开头。这样会移动光标到下一行,如果需要的话还会滚动屏幕。(这两个不同的操作符起源于早些年的(机械)打字机(typewriter)和电传打字机(teletype)。
这是个非常有用的程序。它向我们展示了各种按键如何转化为我们所阅读的字符。大多数常见按键直接转化为它们所表示的字符。但是当你尝试输入箭头、 ESCAPE 、 PAGE UP 、PAGE DOWN 、 HOME、END、BACKSPACE、DELETE 或者 ENTER 按键时,看看会发生什么。也尝试尝试 CTRL 的按键组合,比如 CTRL-A 、CTRL-B 等。
你会发现一些有趣的事情:
- 箭头按键,
PAGE UP,PAGE DOWN,HOME和END都输入 3 或者 4 个字节到终端中,包括27, [和其他一个或者两个字符。这被称作转义序列(escape sequence)。所有的转义序列始于字节27。按下ESCAPE输入单个字节27,这揭示了该按键的名称或者序列的内容。 BACKSPACE是字节127。ENTER是字节13。 它是回车符,也被称为'\r',并不是你设想的那样,一个新行'\n'。(译者注:回车严格来说是将光标移到本行首部位置。'\n'表示将光标移到下一行。因此,现实中的回车符包含了上面两个步骤。计算机这一设计借鉴自机械打字机。如果你不了解机械打字机,请看这个视频 ,视频中主人公先做了回车操作,后做了换行操作。)- 像德国变音符号(German umlauts)这种特殊字符也会产生多个字节。
CTRL-A是字节1,CTRL-B是字节2,CTRL-C是字节3并且不会如你可能料想的那样终止程序。剩下的CTRL按键结合大概会映射 A-Z 到字节 1-26。
按下 CTRL-Q 退出
我们现在知道 CTRL 与字母按键组合似乎被映射到了字节 1-26。我们可以用这个发现来检测 CTRL 按键组合,然后在编辑器中将其映射为不同的操作。所以用它来映射 CTRL-Q 到退出操作(译者注:严格来说是 CTRL-q,为与原文保持一致,不做修改)。
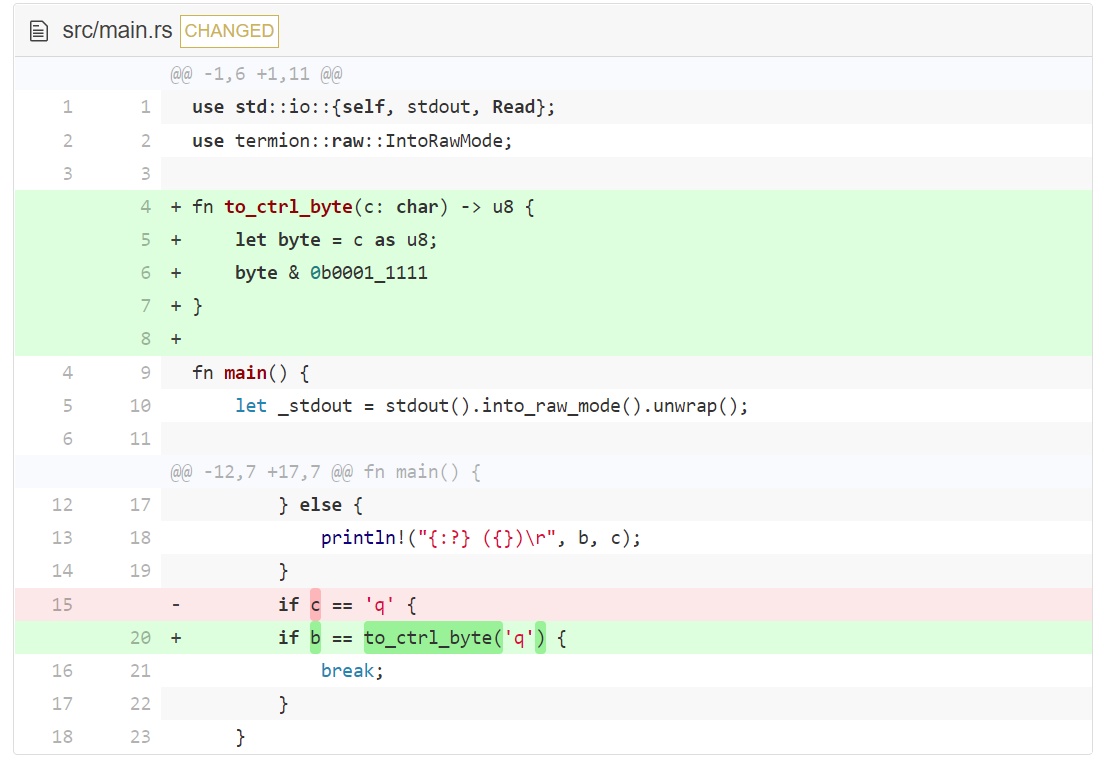
如果你觉得这里的位运算(bitwise-voodoo)对本任务来说太底层,没错你是对的。我们现在正在做的就是为了更好的理解基础知识。当然,我们会在后续章节中重构该代码。
to_ctrl_byte 函数对一个值为 00011111 的字符执行二进制按位与。如果你对此感兴趣,你可以用 println!("{#b}", b); 打印输出变量 b 的二进制表示。({#b} 中的 b 和变量名 b 没有什么关系)。试一试,看看被读取进程序的真实字节。当你比较 CTRL-KEY 按键组合和没有 CTRL 的按键输出时,你会注意到 CTRL 把字节前 3 位比特设为 0 。你如果还记得按位与工作方式的话,就会发现 to_ctrl_byte 做了相同的事。
ASCII 码似乎被有意设计为这样。(可以设置和清除一个比特位来切换小写和大写也是相似的设计。如果你对此感兴趣,可以搞清楚哪个比特(译者勘误:原文是 byte 字节)以及对 CTRL-A 与 CTRL-SHIFT-A 按键组合的影响)
错误处理
是时候考虑怎样去处理错误了。首先我们添加一个 die() 函数,它可以打印错误信息并退出程序。
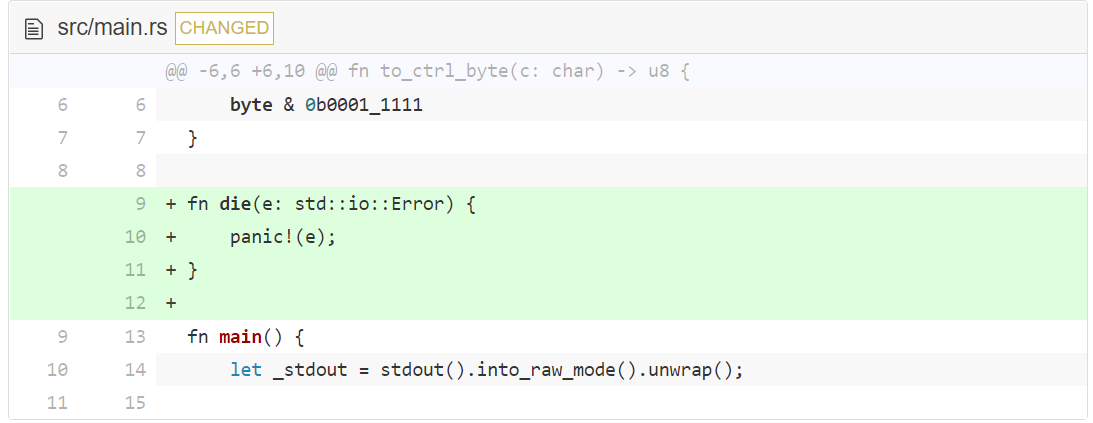
译者注:在 2021 版本的 Rust 中,第 10 行的
panic!需要修改为panic!("{}", e);
panic! 是一个宏,它可以使程序崩溃并发出错误信息。与其他的程序设计语言不同,Rust 不允许你在代码附近添加一些类似于 try..catch 的代码块,来捕获任意可能发生的错误。相反,我们将错误与函数返回值一起向上传播,这将使我们能够在最高级别处理错误。
这种传播能够起到作用的原因是,可能出问题的函数会返回一个叫做 Result 的东西,它要么是我们想要的结果的装包(wrapper)要么就是一个错误。b 中每个值最初是 Result,它要么保存包裹有读取字节的 Ok ,要么持有包裹错误对象的 Err ,它表明在读取字节时发生了问题。为了拿到需要的值,我们可以调用 unwrap(),它是『如果是 Ok 则返回其包装的值,如果是 Err,那就 panic』的缩写。
我们想自己控制(程序)崩溃,而不是当错误发生时任由 Rust panic。 因为,等会儿,我们想在程序崩溃之前清空屏幕,不要让用户看到一半的(half-drawn)输入。现在,让我们简单检查一下是否有错误,然后调用 die,它为我们 panic。
让我们现在实现它。
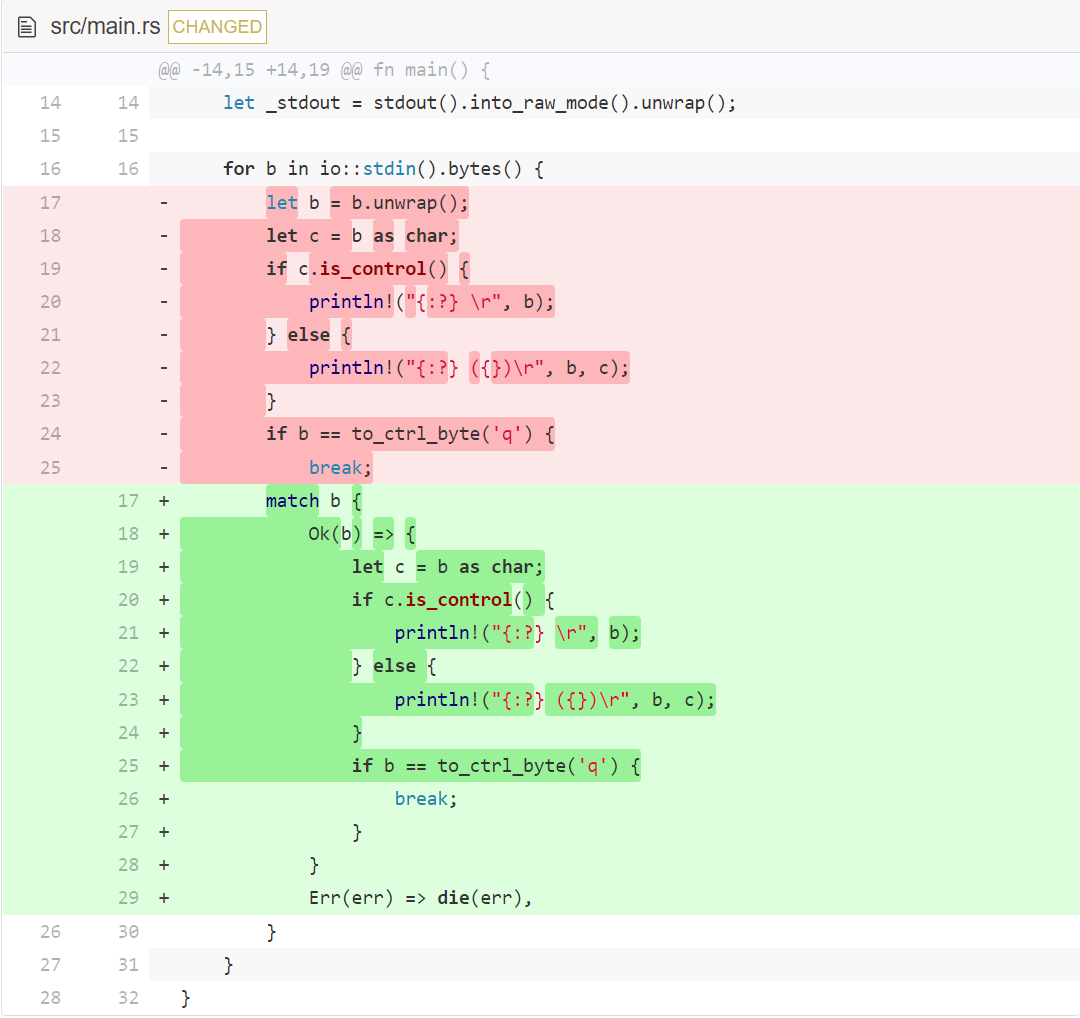
这里有一些需要注意的东西。我们故意忽略 into_raw_mode 的错误。我们的错误处理主要是为了避免乱码输出,而乱码输出只有在我们重复向屏幕写入时才会发生,所以对于我们的目的来说,在我们的循环开始之前没有必要进行任何额外的错误处理。
然后,我们引入一个新概念:match 。现在,你可以把 match 看成是一个超大版的 if-then-else 。它接收原始变量 b。b 要么包含我们想包裹进 Ok 的值,要么是包裹进 Err 的错误。看一下简单的例子:
//...
match foo {
Ok(bar) => {
//...
},
Err(err) => {
//...
}
}
//...
这段代码可以这样理解:如果变量 foo 是一个 Ok,解包其内容,绑定到变量 bar 中,然后执行下面的代码块。在我们的例子中,我们再次使用了变量隐藏,所以被包裹的变量 b 会被解包并绑定到 b 上。
我们会在后面进一步研究 match,这里是文档,以免你对此感兴趣。
总结
本章关于进入原始模式的内容到此结束。我们学习了很多关于终端和 Rust 基础部分的内容。在下一章节中,我们将做更多的终端输入/输出处理,并利用它来绘制屏幕,同时允许用户移动光标。我们也会重构代码,使其更加地道,但是首先,我们需要搞清楚地道的含义。